
- Thu 06 June 2019
- Community
- Ankur Sinha
- #Software development, #RPM, #Packaging
Given the large number of software updates we published recently, we thought this is a good chance to explain how the NeuroFedora team (and the Fedora package maintainers team in general) stays on top of all of this software that is constantly being updated and improved.
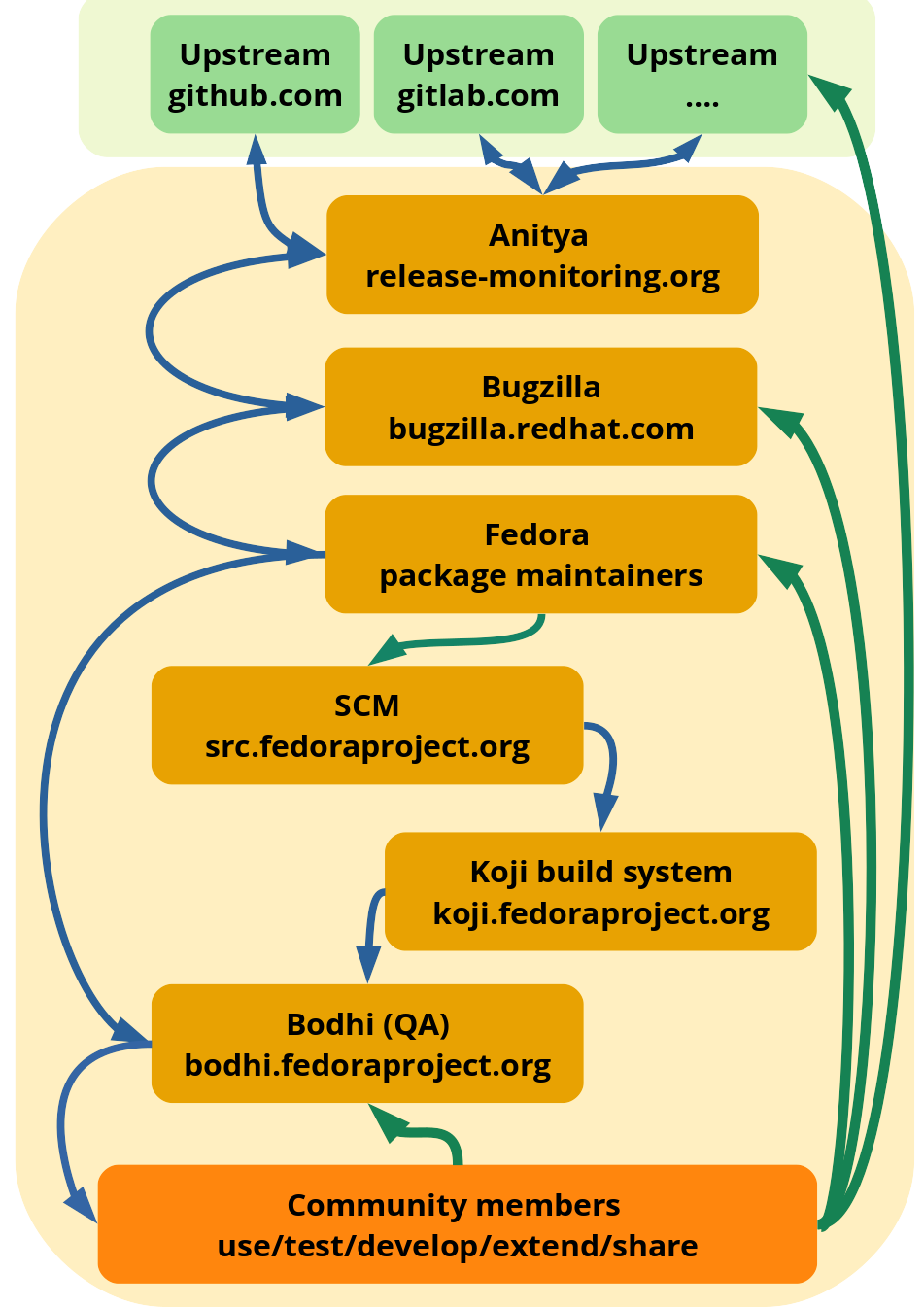
As the (simplified) figure shows, there is a well defined process to ensure that we keep our software in good shape---updating it all in a timely manner. The Fedora Infrastructure team maintains lots of tools to enable the community in this aspect too, and all of these tools continuously evolve as the community moves to newer directions.
In the sections below, we go over the process step by step.
1. Upstream releases a new version
It all starts with upstream releasing a new version.
Upstream are the developers of the software. We at NeuroFedora (and most Linux distributions) are downstream: we take developed software, build and integrate it all, and provide it in easily installable packages to users.
On Fedora, these packages are provided as rpm archives via the
repositories. Other distributions may use other formats.
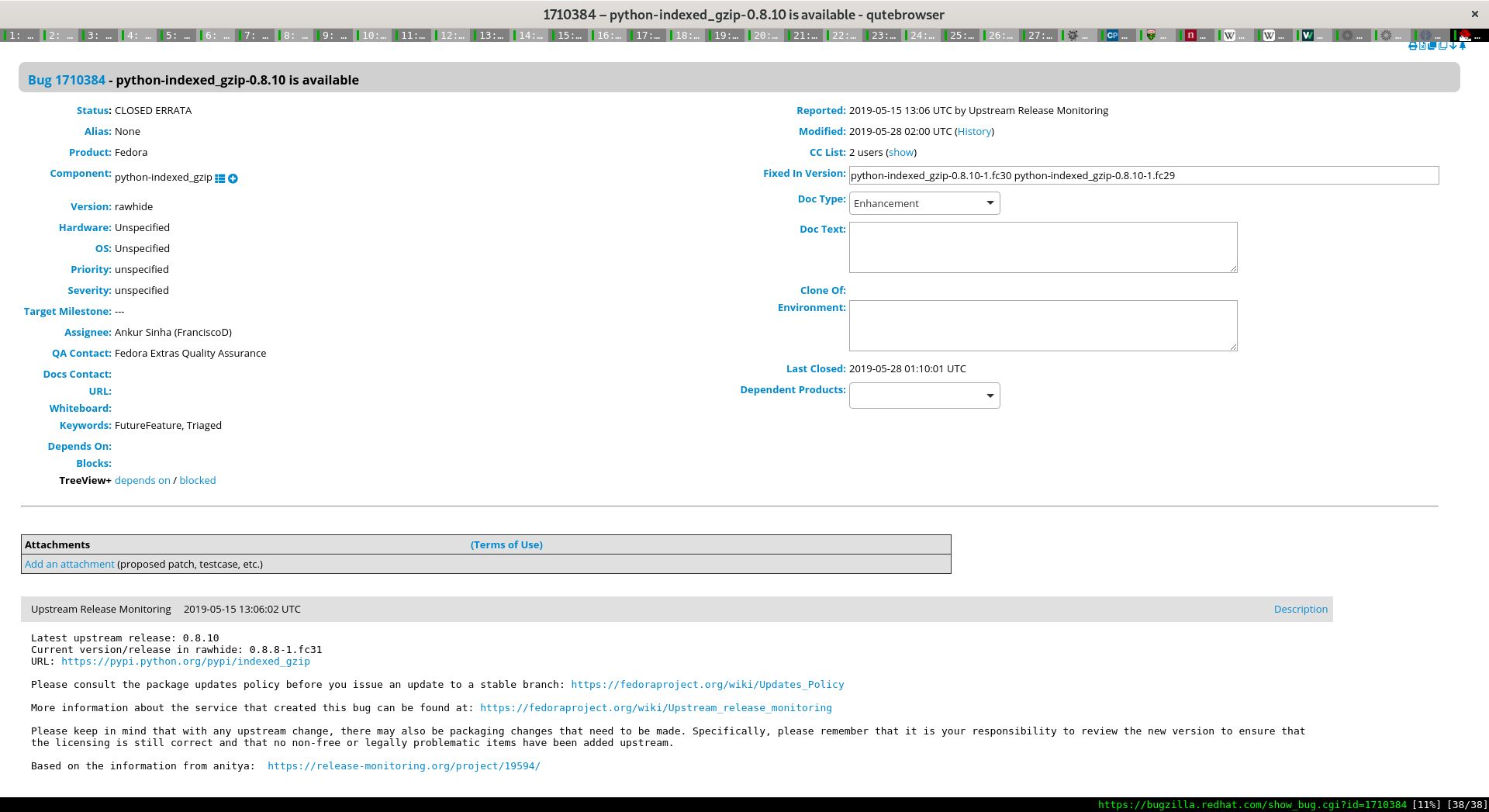
2. Anitya notifies us maintainers via Bugzilla
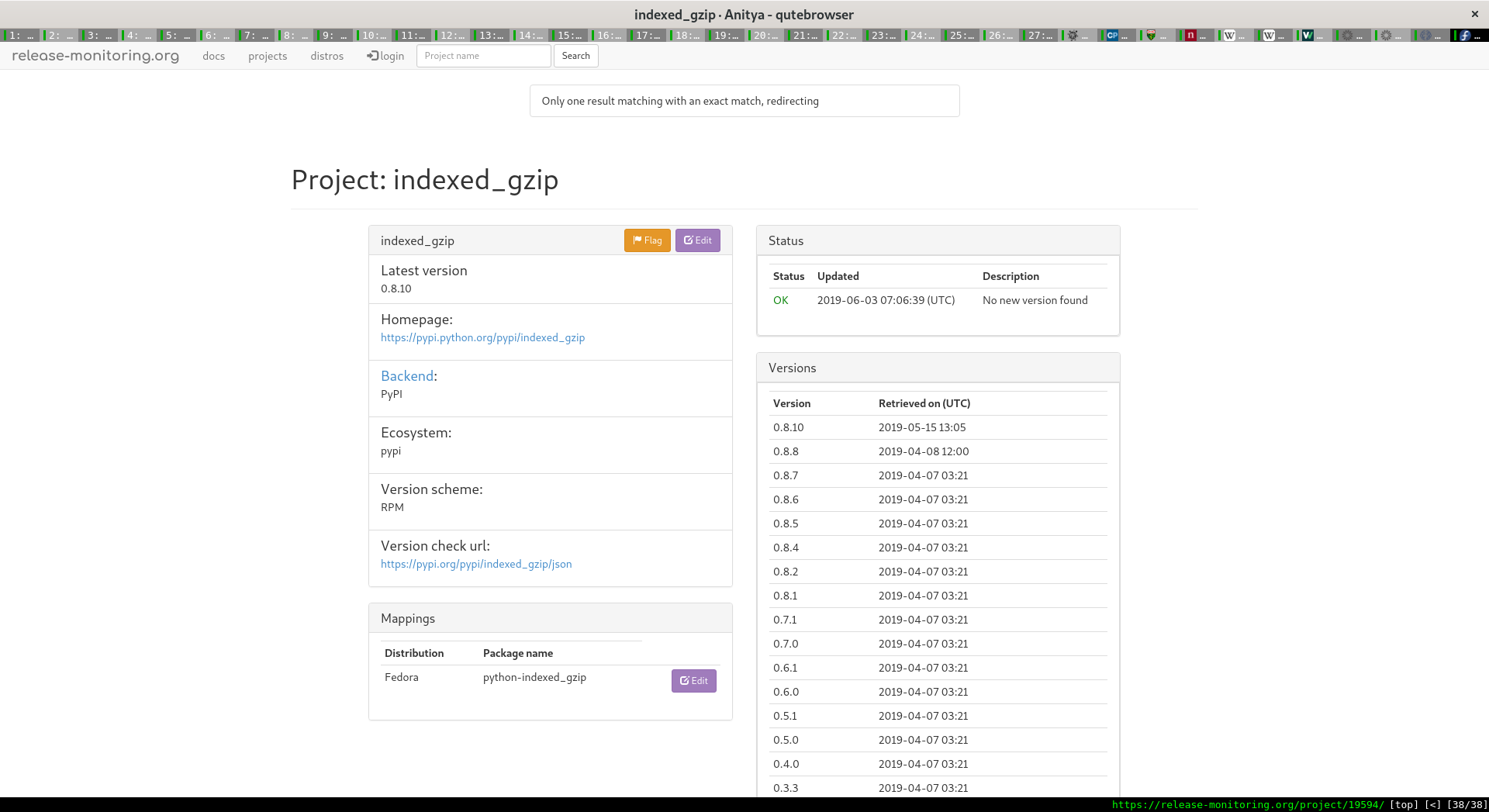
Anitya runs at https://release-monitoring.org and monitors upstream for new versions. Anitya is able to monitor different upstream release methods such as Github, PyPi, Sourceforge, Gitlab, and so on. When Anitya detects a new version it first checks to see what version of this software we are currently providing in Fedora. If it sees that the Fedora version is older than the new upstream version that it has detected, it files a bug on our community bug tracker at https://bugzilla.redhat.com notifying the maintainers.
TIP: you can use the Fedora packages application at
https://apps.fedoraproject.org/packages to search the full list of software
that is currently included in Fedora. If you already know the name of the
package, you can use https://bugz.fedoraproject.org/<package name>
(replace <package name> with the name of the package, such as
nest) to go straight to a package's summary page.
3. Maintainers test and update the Fedora package
Once the bug has been filed, the next steps require manual work. There are tools to make it all easier, but this is where we humans come in.
One of the NeuroFedora package maintainers notices the bug and begins to work on it. All notifications from bugzilla are sent to the neuro-sig mailing list, so the team is usually always aware of these.
First, we fetch the new source code and test it to see how it has changed in the new release. Is it a minor release with bug-fixes and enhancements, or is it a major release where lots of functionality has changed?
Sometimes, especially with development libraries, there are API/ABI changes that make the new version incompatible with the older ones. In such cases, we have to see how all other software that depends on these is affected. This is documented in the community policy on updating software. The idea is that when new versions of software are released, as package maintainers, one of our duties is to ensure that the new versions do not break existing systems for our users.
If there is software that does not work with the latest versions, we maintainers try to help developers update their code. Here are some examples where we've notified maintainers:
- Neuron: use newer libstdc++
- Neuron: use a more recent SUNDIALS version
- VXL: use newer openjpeg2
- VXL: use newer DCMTK
When possible, we do try to provide patches and open pull requests. However, this depends on how much time we maintainers have and of course, it also depends on the complexity of the codebase.
In general, we try to stay as close to upstream as possible. This page lists the advantages of doing so: https://fedoraproject.org/wiki/Staying_close_to_upstream_projects
3a. Maintainers update the spec file and build new rpms
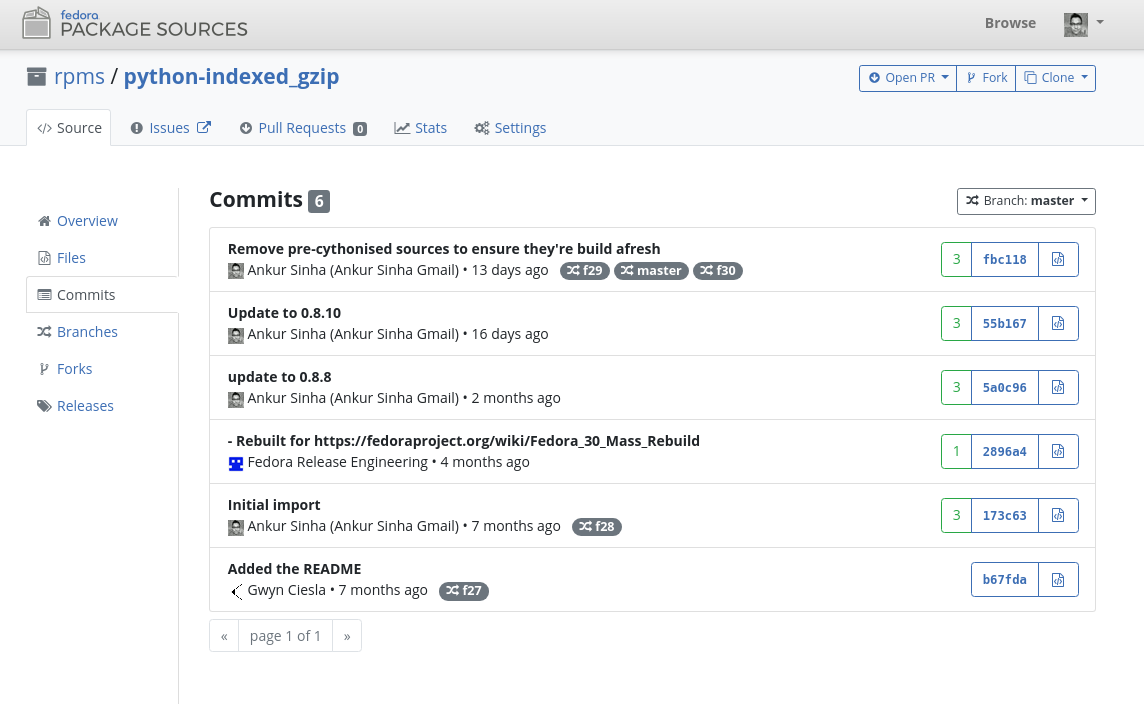
If everything seems to work fine after we've managed to fix any issues, we begin to update the Fedora package. The first step here is to update the spec file. The spec file resides in the package's dist-git repository on https://src.fedoraproject.org/rpms/ where other Fedora tools can access it. When this has been updated to build the newest release, we queue up a new build on the Koji build system.
spec files provide instructions that tell the rpmbuild tool how to
build the software, and where all its files should go in the rpm
package. More information on the process can be found here.
You can see a relatively simple spec file for python-indexed_gzip here.
This one
for the nest simulator, however, is a lot more complex since we must
build it with MPI support also. If you want to see a real scary spec file,
though, look at this one for
the texlive package. It is auto generated from the texlive sources, but you can imagine how hard it must
be to debug.
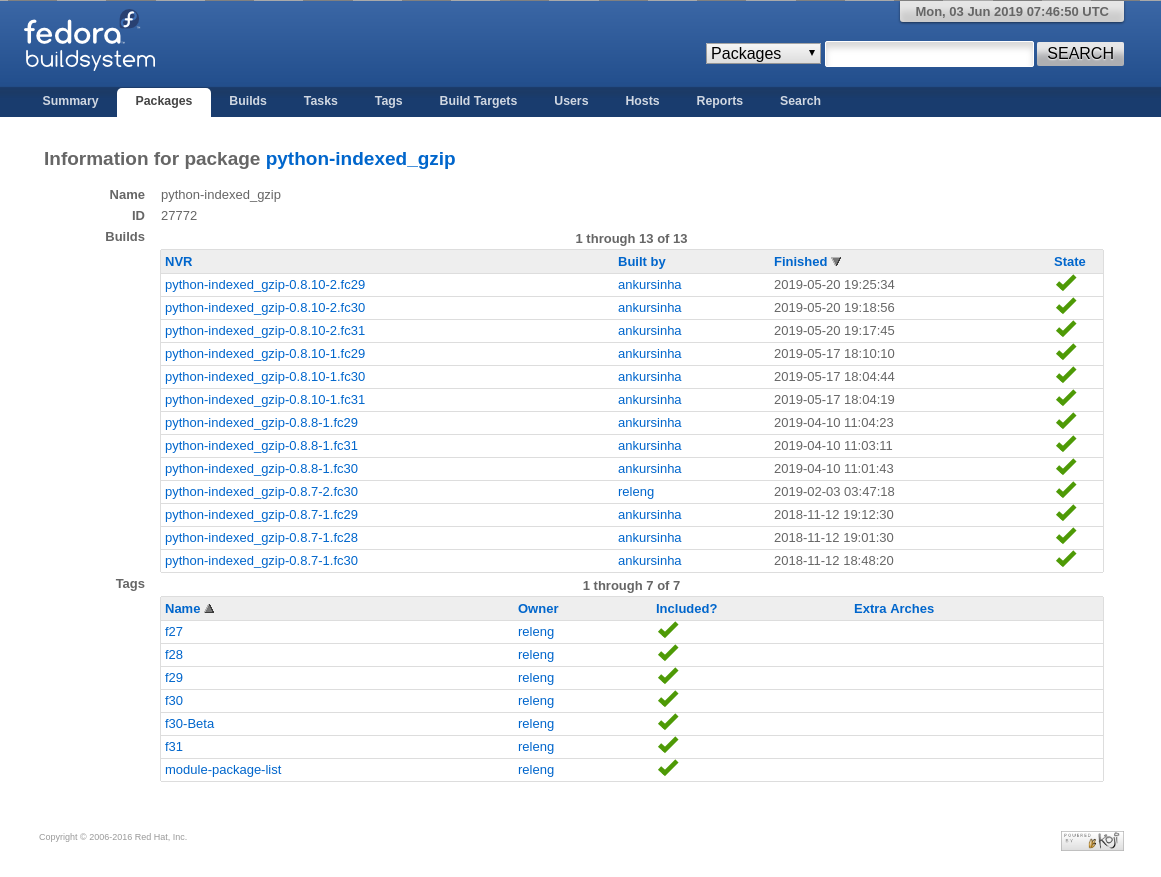
The build system handles all our supported arches unless told not to do so.
Currently, the Fedora community supports: x86_64, i686, armv7hl,
aarch64, ppc64le, s390x. More information on these architectures can be found
here.
4. Quality assurance: the community tests the updated packages
Once the builds have completed successfully, we push the builds to our Quality Assurance pipeline for testing.
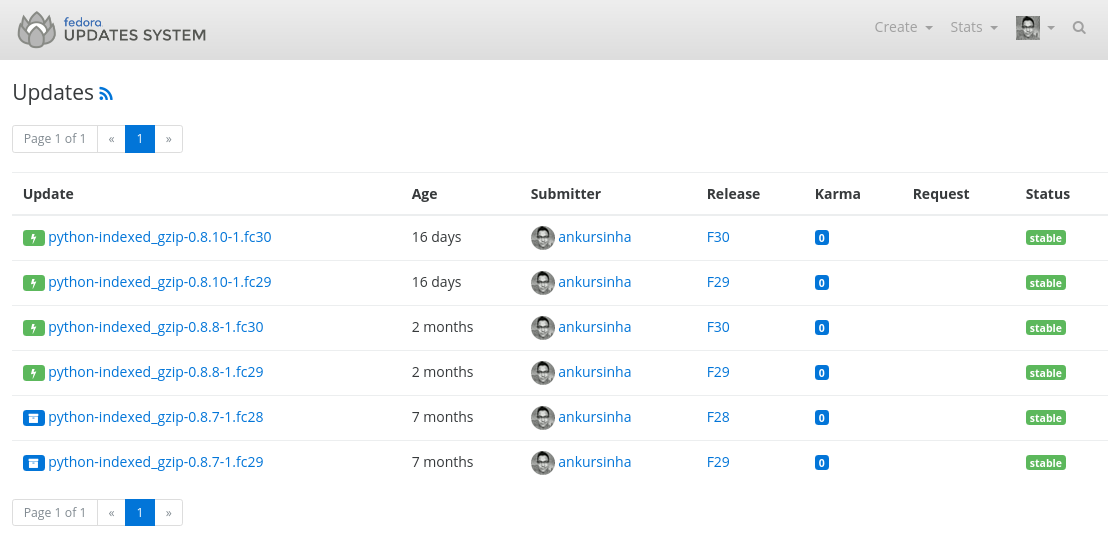
It isn't enough to get the software to build correctly. We must also ensure that it works correctly. The pipeline lets community members (including users) test these updated packages in a staging repository.
You can help test these updates. All you need to do is install them, and provide feedback. This is all explained here.
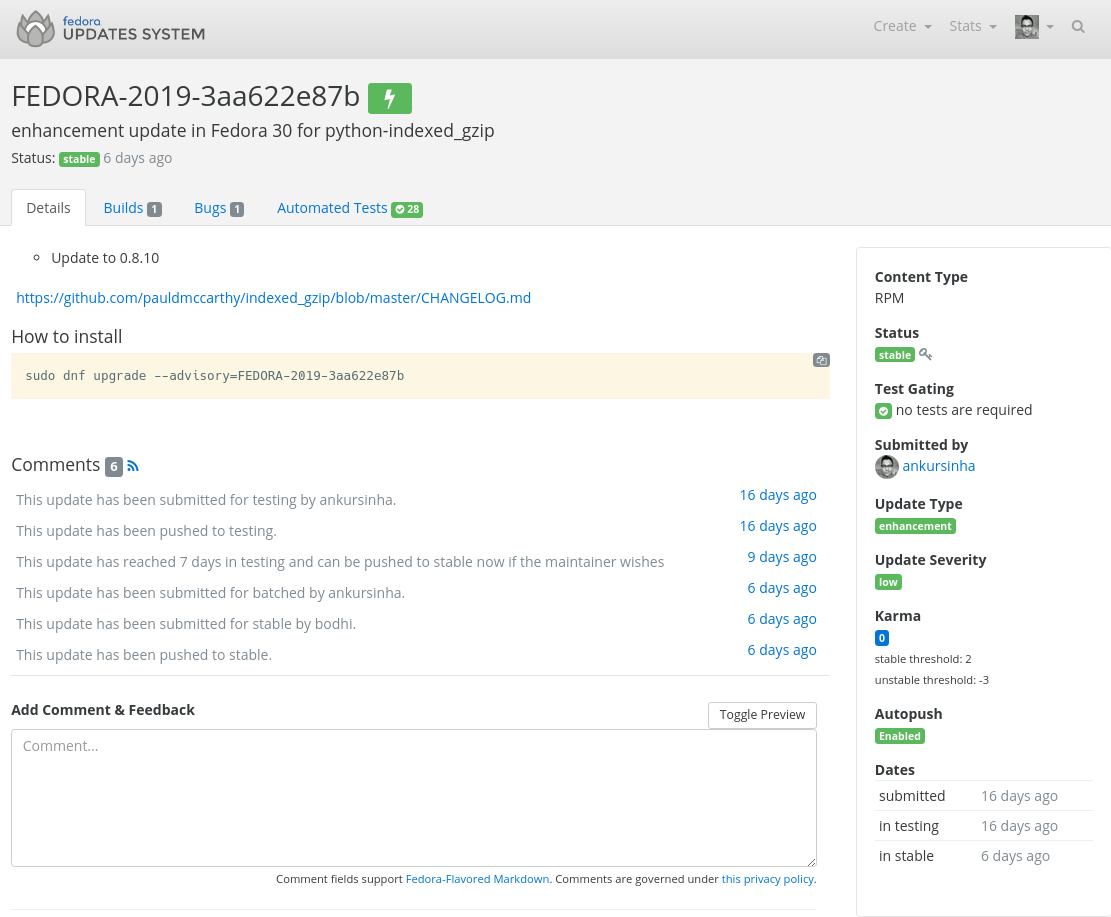
If the packages pass the community's battery of automated checks, and testers provide positive feedback on their functioning, they are then moved from the staging repositories to the stable repositories where they are available to all users.
These general steps are not limited to the NeuroFedora team. They are followed by all Fedora community. package maintainers
Join the community!
Since community projects aren't profit focussed, instead of money, the resource we most need is man-power. Each new contributor increases the sum total man-power possessed by the community and this enables us to work with more software, help more developers, improve all of this software in general---get more work done.
If you've gotten this far, you would have probably realised that there is quite a bit of work to be done, and there are ample opportunities where you can help in this area of NeuroFedora/Fedora. You can:
- suggest software for inclusion
- package and maintain software
- test packaged software
- file bugs and report issues
- help maintain the tools that are required to keep the community ticking
More information on all of this is included in our documentation here. The easiest way, though, is probably just to have a chat with the team. Catch us anytime on our communication channels.
NeuroFedora is volunteer driven initiative and contributions in any form always welcome. You can get in touch with us here. We are happy to help you learn the skills needed to contribute to the project. In fact, that is one of the major goals of the initiative---to spread technical knowledge that is necessary to develop software for Neuroscience.